
Meta 已 确认 将重新启动利用其英国用户群的公开 Facebook 和 Instagram 帖子来训练其人工智能系统。
该公司声称,它已“将监管反馈纳入”修订后的“选择退出”方法,以确保其“更加透明”,正如其博客文章所言。该公司还试图将此举描绘成使其生成式人工智能模型能够“反映英国文化、历史和习语”。但目前尚不清楚其最新的数据抓取究竟有何不同。
Meta 表示,从下周开始,英国用户将开始看到应用内通知,解释其正在做什么。该公司计划在未来几个月开始使用公共内容来训练其人工智能——或者至少通过 Meta 提供的流程对用户未主动反对的数据进行训练。
三个月前,Facebook 的母公司因英国监管压力暂停了该计划,英国信息专员办公室 (ICO) 对 Meta 可能如何使用英国用户数据来训练其生成式人工智能算法以及它如何获得人们的同意表示担忧。爱尔兰数据保护委员会是 Meta 在欧盟的主要隐私监管机构,在收到欧盟多个数据保护机构的反馈后,该委员会也反对 Meta 的计划——目前尚不清楚 Meta 何时或是否会在欧盟重启其人工智能训练工作。
就背景而言,Meta 一段时间以来一直 在美国等市场 推动其基于用户生成内容的人工智能,但欧洲全面的隐私法规给它以及其他希望以这种方式扩大训练数据集的科技公司 带来了挑战。
尽管欧盟有隐私法,但早在 5 月份,Meta 就开始通知该地区的用户 即将进行的隐私政策变更,称它将开始使用评论、与公司互动、状态更新和照片及其相关标题的内容进行 AI 训练。它辩称,这样做的原因 是它需要反映“欧洲人民的多种语言、地理和文化背景”。
这些变化原定于 6 月 26 日生效,但 Meta 的声明促使隐私权非营利组织noyb (又名“不关你的事”)向欧盟成员国提起了十几起投诉,称 Meta 违反了欧盟《通用数据保护条例》(GDPR)的各个方面——该法律框架是欧盟成员国国家隐私法的基础(当然,也是英国《数据保护法》的基础)。
投诉针对的是 Meta 使用“选择加入”机制来授权处理,而不是“选择退出”——认为应该先征求用户的许可,而不是采取行动拒绝对其信息的新用途。Meta 表示,它依赖的是 GDPR 中规定的法律基础,即“合法利益”(LI)。因此,尽管隐私专家怀疑 LI 是否适合用于此类个人数据,但它仍坚持认为其行为符合规定。
Meta曾试图依靠这一法律基础 来证明其处理欧洲用户信息以进行微定位广告的合理性。然而,去年欧盟法院裁定,该法律基础 不能用于 该场景,这也引发了人们对 Meta 通过 LI 钥匙孔推动 AI 训练的尝试的质疑。
然而,鉴于英国已不再是欧盟的一部分,Meta 选择在英国而非欧盟启动其计划,这一点颇具说明意义。尽管英国数据保护法仍然以 GDPR 为基础,但 ICO 本身已不再属于同一监管执法俱乐部,并且经常在执法方面手下留情。英国立法者最近也考虑放松国内隐私制度的管制。
选择退出反对意见
Meta 的做法首次引起众多争论,其中之一就是它为 Facebook 和 Instagram 用户提供的“选择退出”流程,让他们的信息不被用于训练人工智能。
该公司没有直接为用户提供“选择加入/退出”复选框,而是让用户费尽周折,多次点击后才找到一个反对表格,这时他们必须说明为什么不希望自己的数据被处理。他们还被告知,是否接受这一请求完全由 Meta 自行决定。尽管该公司公开声称会接受每一项请求。
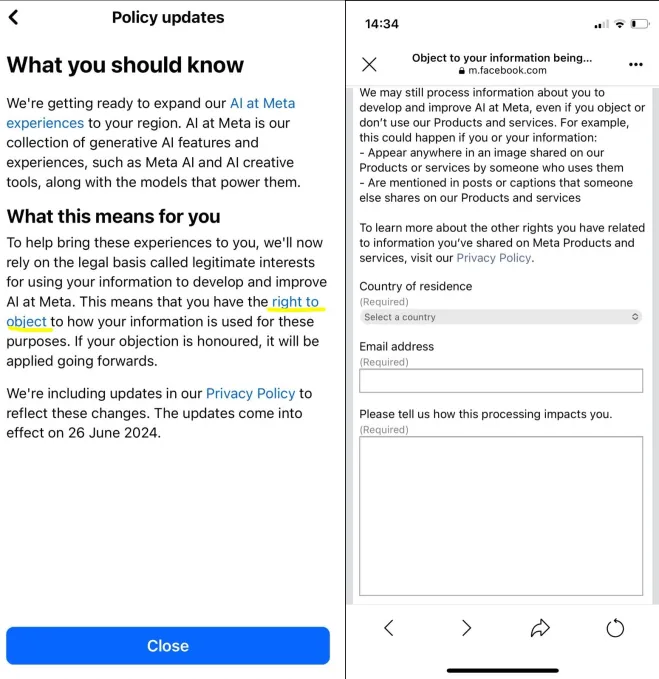
这次,Meta 坚持使用异议表格的方式,这意味着用户仍然必须正式向 Meta 提出申请,告知他们不希望自己的数据被用于改进其人工智能系统。Meta 表示,之前提出过异议的用户无需重新提交异议。但该公司表示,这次他们简化了异议表格,采纳了 ICO 的反馈意见。尽管该公司尚未解释为什么会更简单。因此,目前,我们所知道的只是 Meta 声称该流程更简单。
ICO 技术和创新总监 Stephen Almond 表示,随着 Meta 推进其使用英国数据进行 AI 模型训练的计划,它将“监控情况”。
Almond 在一份声明中表示:“Meta 必须确保并证明其持续遵守数据保护法。我们已经明确表示,任何使用用户信息来训练生成式人工智能模型的组织都需要对人们的数据使用方式保持透明。组织应遵循我们的指导,在开始使用个人数据进行模型训练之前采取有效的保障措施,包括为用户提供一条明确而简单的反对处理途径。”